
Embedded verifier for mongosync
This post describes the embedded verifier for mongosync, which is a project I designed and led the implementation of in my time at MongoDB.
Context
My current role is on the Cluster-to-Cluster team at MongoDB. Our team is responsible for (among other things) a tool called mongosync. In late 2023, we decided to write a verification tool that would live alongside mongosync to verify that it was working correctly. I was tapped to write the design and lead the project.
Mongosync is a tool that migrates data from one MongoDB cluster to another. A cluster is a logical MongoDB server, consisting of multiple nodes that replicate data among themselves. Clusters are either replica sets (a single group of nodes that share the same data) or sharded clusters (multiple replica sets, each with their own subset of the data, plus some other components).
While normal MongoDB replication handles moving data around inside a single cluster, mongosync is a tool to copy the contents of one cluster into an entirely separate cluster. One of the most important business cases for mongosync is to help customers move from on-prem deployments of MongoDB into Atlas, which is MongoDB’s cloud product. This is a use case for which normal replication does not work: you cannot add an Atlas node to your existing on-prem replica set.
Mongosync is an online tool: it migrates data from a source cluster to a destination cluster while the source is still receiving writes from the customer’s application. Users have to take a very small amount of downtime (on the order of several minutes) to finalize the migration. This makes Mongosync a much more attractive option for migration than using mongodump to take a database snapshot from one cluster and mongorestore to restore it to another: a process can take a very long time. (Our team also maintains the database tools, including dump and restore.)
Because mongosync is online, it’s also much more complicated than mongodump or mongorestore: it needs to be able to deal with the source cluster changing out from underneath it while it runs. MongoDB provides a feature we use to do this: change streams are used to get information about writes happening on the source cluster in nearly real time. Mongosync works in two phases: first it copies things in bulk (we call this “collection copy”), and then applies all of the change events to capture writes that happened during collection copy (this phase is called “change event application”).
Users monitor the progress of the process over an HTTP API; when mongosync
reaches a steady state during change event application, they finalize the
migration. To do so, they must stop writes on the source cluster (so that we
have a known final state) and call the /commit endpoint. At this point,
mongosync enters a phase called “cutover”, where it does any final data
copying necessary, finalizes some other things on the destination (we relax
some constraints during the migration to improve write performance), then
allows users to start using their destination cluster for reads and writes.
When you’re writing a data migration tool like this, the Prime Directive is very simple: don’t screw up the users’ data. When the migration is complete, the destination cluster must match the source cluster exactly. Mongosync has very extensive testing – in some cases, even more extensive than the MongoDB Server itself – to be sure that we’re resilient against all sorts of weird scenarios that can come up in the wild. (For example: we test the behavior of mongosync during server elections and during random node failures, we randomly kill and restart mongosync during tests, we randomly force some number of writes to be retried or arbitrarily dropped; you get the idea.)
Unfortunately, in late 2023, we had to issue a number of Critical Advisories (CAs) for mongosync. There were a few extreme edge cases where we could, in theory, lose user data. Some of these were caught by our internal testing (but frustratingly, after release), and others were interactions with surprising edge-case behavior from the MongoDB Server.
We started a big correctness push on the team, with the goal of eliminating the need to issue any more CAs for mongosync. There were a lot of angles we could take on the problem, but the biggest one was verification. We wanted some way of telling customers “Hey, your migration is finished, and we have verified that it went the way we thought it did: all your data is safe, and you can sleep easy tonight.”
Prior to this, our verification story was fairly light. Our documentation told users to verify the data, but in practice this usually meant counting the documents on both source and destination and spot-checking documents on both clusters until you were satisfied that the migration hadn’t gone horribly wrong. (A “document” is a single MongoDB record, like a row in a relational database.) There was also a standalone verifier, but at the time, we weren’t really confident that it was fully correct either. We needed something better.
Design and Implementation
Constraints and up-front decisions
The verifier had a number of design constraints:
- The verifier needed to run inside of mongosync. The pre-existing standalone verifier was hard for users to operate, because it requires coordinating a second binary. We wanted anyone running mongosync to get the benefits. (This also meant that the verifier had to be written in Go.) It’s technically the “embedded verifier”, to differentiate it from the standalone verifier, but for brevity here I’ll just call it “the verifier.”
- The verifier must do full document verification. Spot-checking a few documents here and there would not provide sufficient confidence.
- The verifier could not substantially increase mongosync’s cutover time. The online nature of mongosync is its biggest asset: if we provided a verification solution that required hours of downtime, no one would use it.
- For the verifier, correctness is paramount. When there is a choice between correctness and anything else (notably: performance), correctness wins. It is not acceptable for the verifier to incorrectly report success. Ideally, it would never incorrectly report failure either, but it is acceptable to fail a migration that should have succeeded: the opposite is not true.
We made a few additional important design decisions up front:
- The verifier and mongosync should share as little code as possible. This is
an example of the Swiss cheese model.
Mongosync is going to have bugs, and the verifier is going to have bugs (because all software has bugs), but we definitely don’t want them to be the same bugs. This meant we ended up reimplementing some code that probably wasn’t strictly necessary to reimplement, but increased the overall confidence in the tool. (In general, the verifier’s versions of the code are simpler than mongosync’s, which is a nice benefit too.) - The first version of the verifier would store all its data in memory. One the one hand, this sucks: it means the verifier would require a lot of memory, and that – unlike mongosync – if the process crashed, you’d need to restart verification from scratch. On the other hand, it meant that we could get the first version done faster, and worry about persisting its data to durable storage later. This decision turned out to be a good one: we are still (as I write this in mid-2025) in the process of implementing persistent storage, and have run into a number of snags along the way. Meanwhile, the in-memory version has been running in production for months.
- For every collection (like a table in a relational database), we would generate a single checksum. This means that during cutover, all we need to do is compare checksums for corresponding collections on the source and destination. This is quick enough to do that it meets our performance target: even if a customer has a millions of collections (which would be at the extreme end of the bell curve), iterating through a map of millions of entries to compare 64-bit ints takes less than a second on reasonable hardware.
Design details
At this point, I took these basic constraints and very high-level design and wrote the full design, which is described in some detail here. I’ve left out a lot of the specific, since mongosync and the verifier are proprietary.
I wanted the verifier to be very easy to call from inside mongosync. This
means that mongosync only needs to import a single package. The highest-level
interface is very straightforward: you call New(options) to get a
verifier object, verifier.Run(ctx) to start it, and
verifier.GenerateResult() to instruct it to stop processing and do the final
comparison. GenerateResult returns a Result object that you can inspect to
determine whether or not the clusters match.
Most of the logic isn’t in the verifier object itself: it lives in an
abstraction called the auditor. The verifier struct has two ClusterAuditor
objects, one for both the source and destination clusters. An auditor is
responsible for generating checksums for a single cluster.
One of my guiding design principles for the verifier is “simpler is better.” It is critical that the verifier is correct, so it’s important that it is easy to reason about: it needs to be readable, maintainable, and not have lots of dark corners. Putting the logic into a single-cluster abstraction is one of the most important examples of this. You could imagine a design that talked to both clusters at the same time, but that means you’d always need to test against two clusters, and be sure that you never mixed them up in the code. Because the verifier’s design is just “do the same thing in two places, and compare them at the end,” it simplifies things a lot. Most notably, it’s easier to test: you only need a single cluster, and you can test a full lifecycle from start to finish. The final comparison algorithm is not even interesting (it’s effectively iterating through two maps and asserting they match), and all of the complexity is in how we generate those maps.
The auditor’s job is to generate a checksum for every collection on the cluster. That checksum is computed by XORing together the hashes of every individual document in the collection. (It’s possible we could end up with hash collisions here, but exceedingly unlikely. Importantly, we’re not hashing arbitrary data: we know that every document must be valid BSON, which severely limits the input domain.)
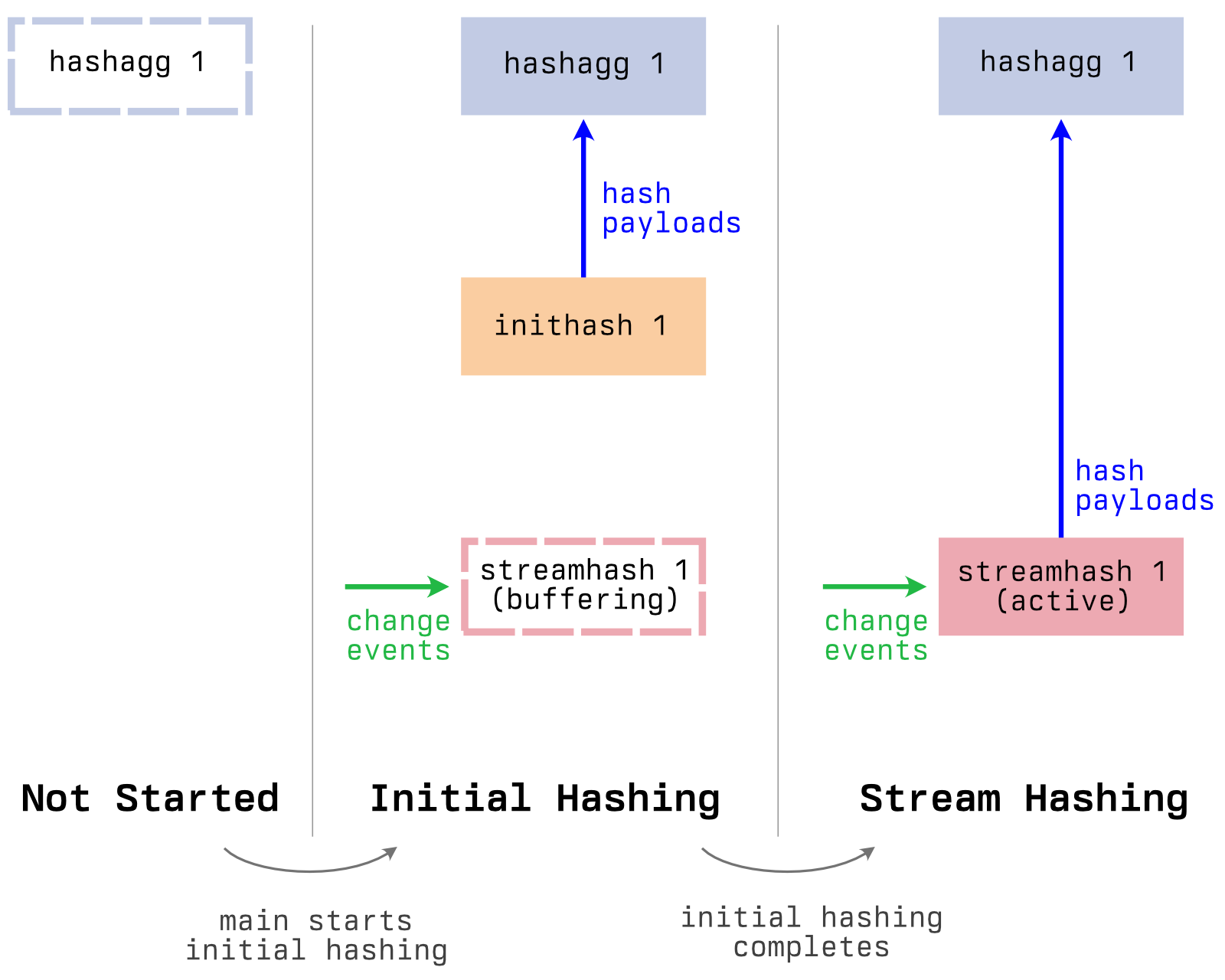
To generate and maintain the collection checksum, we do this, for every collection:
- First, do an initial scan of the collection. For every document, we generate a 64-bit hash; all of these hashes are XORed together to create the collection checksum. This phase is called initial hashing.
- While the initial scan is happening, we buffer change events from the global change stream in memory.
- When the initial scan finishes, we move to the stream hashing phase. First, we process all the buffered change events for that collection, updating the checksum as necessary.
- Once the buffered change events are processed, we continue to process all new change events for the collection in the same way. This stream hashing phase ensures the collection checksum is always a single 64-bit integer that represents all individual document hashes in the collection, XORed together.
Because each collection is independent, this design is reflected in the abstractions. For every collection, the auditor has three components:
- An “initial hasher,” which is responsible for the initial collection scan.
- A “stream hasher,” which is responsible for buffering change events (during initial hashing), and then processing those change events (during stream hashing).
- A “hash aggregator,” which is responsible for maintaining the collection
checksum. It receives document hashes from the initial hasher (during
initial hashing) and the stream hasher (during stream hashing), and
maintains the checksum. The hash aggregator maintains a map of every
document’s ID and its hash value, so that it can XOR documents out of the
collection checksum when they are deleted. This is where the verifier’s
enormous memory use comes from: if there are a million documents in a
collection, the aggregator for that collection will have a million
_idvalues and 64-bit integers in its map.
This diagram shows the basic lifecycle of a single collection inside the auditor:
The verifier is written in Go, so these components each run in a different goroutine, and communicate primarily over channels. If I were redesigning the verifier, I might make a different decision about this. I mostly agree with this post about how Go channels have very confusing semantics, and we were bitten by a lot of them during implementation. In particular: once you spin up an auditor with all these goroutines, unless you’re very careful all of the time (not a great recipe for programming success), it’s very easy to accidentally write code that causes something to unexpectedly hang forever. This represented a large class of bugs we dealt with while implementing the design: we ended up adding some abstractions to make this a little better, but if I were starting from scratch, I would probably try to sidestep the problem altogether.
Anyway, where was I? The auditor, right!
The three components for each collection are wrapped inside an abstraction
called the “hash controller.” The auditor has one controller for each
collection, stored in a map. This map is keyed by the collection’s UUID, which
is assigned by MongoDB itself. We do this because mongosync and the verifier
and mongosync both support DDL operations: you can rename a collection during
a migration. When you do that, the collection’s name changes (obviously), but
its UUID does not. Keying everything by UUID means we can avoid a bunch of
potential correctness issues: we must deal with the case where a user has
some collection collA, renames collA to collB, then creates a new
collection named collA. (If this seems convoluted to you, it does to me too,
but that’s the problem space we’re working in: we have to support any wild and
crazy thing users might do.)
The auditor has a handful of other components, the most important of which is the “change stream reader.” That component is responsible for reading the global change stream for the cluster. For every write (CRUD operations to individual documents and DDL operations on databases and collections), the verifier gets a “change event.” For individual documents, we get the full document in the change event; the change stream reader is responsible for hashing that document and sending a payload over a channel back to the auditor. For CRUD events, the auditor then dispatches each payload to the relevant stream hasher for the collection; for DDL events, the auditor spins up new goroutines (for create events), destroys existing goroutines (drop events), or handles it in some other way (outside the scope of this discussion).
So, to recap: the auditor talks to a single cluster; the verifier has one for the source and one for the destination. For every collection on the cluster, it reads every document in the collection and generates a checksum that is the XOR of every individual document in that collection. It also reads the change stream to account for updates to those documents as it goes. When it’s done running, the auditor ends up with a big in-memory map like this:
uuid_1: {
namespace: "db1.coll1",
checksum: 0xf5c5ad848cfdb697,
},
uuid_2: {
namespace: "db2.coll2",
checksum: 0xd4720e87065422af,
}
Once the auditors have run, the final verification is very simple. The verifier first gets the maps from each auditor and re-keys them by namespace, because collections on the source and destination will always have different UUIDs. Once it’s done that, generating a result is very straightforward:
- If there are source collections that are missing on the destination: fail. ❌
- If there are destination collections that are not on the source: fail. ❌
- If the checksums for corresponding source and destination collections do not match: fail. ❌
- Otherwise: success! Everything worked. 🎉
Impact
Implementation of this design was not as smooth as we would have liked (largely due to counterintuitive or just plain buggy behavior from MongoDB itself), but this basic design has, so far, stood the test of time. Testing for the verifier was very extensive, and uncovered a lot of bugs in both the verifier implementation and MongoDB itself (see a case study for one of the Mongo bugs we found). Because correctness is so critical, we were not willing to release the verifier until we were extremely sure it was right.
We did release the verifier in late 2024, after 10 months or so of work. Since then, it’s been running in production with very few problems. It’s not entirely bug-free, and it has (as we predicted) caused some migrations to fail where it probably should not have. That said, none of its bugs have been correctness bugs: in every case the verifier has failed, it has failed safely.
When we set out to start the verifier project, we could not say confidently that any mongosync migration was fully correct. The embedded verifier has changed that: if the verifier allows a migration to cut over, we are now very confident that the user’s data is safe and secure in its new home.